
MMM-272: Enhanced Text-to-Motion Generation
Extended the Masked Motion Model (MMM) to support 272-dimensional motion representation, achieving state-of-the-art text-to-motion generation with improved BVH conversion quality.
Project Requirements
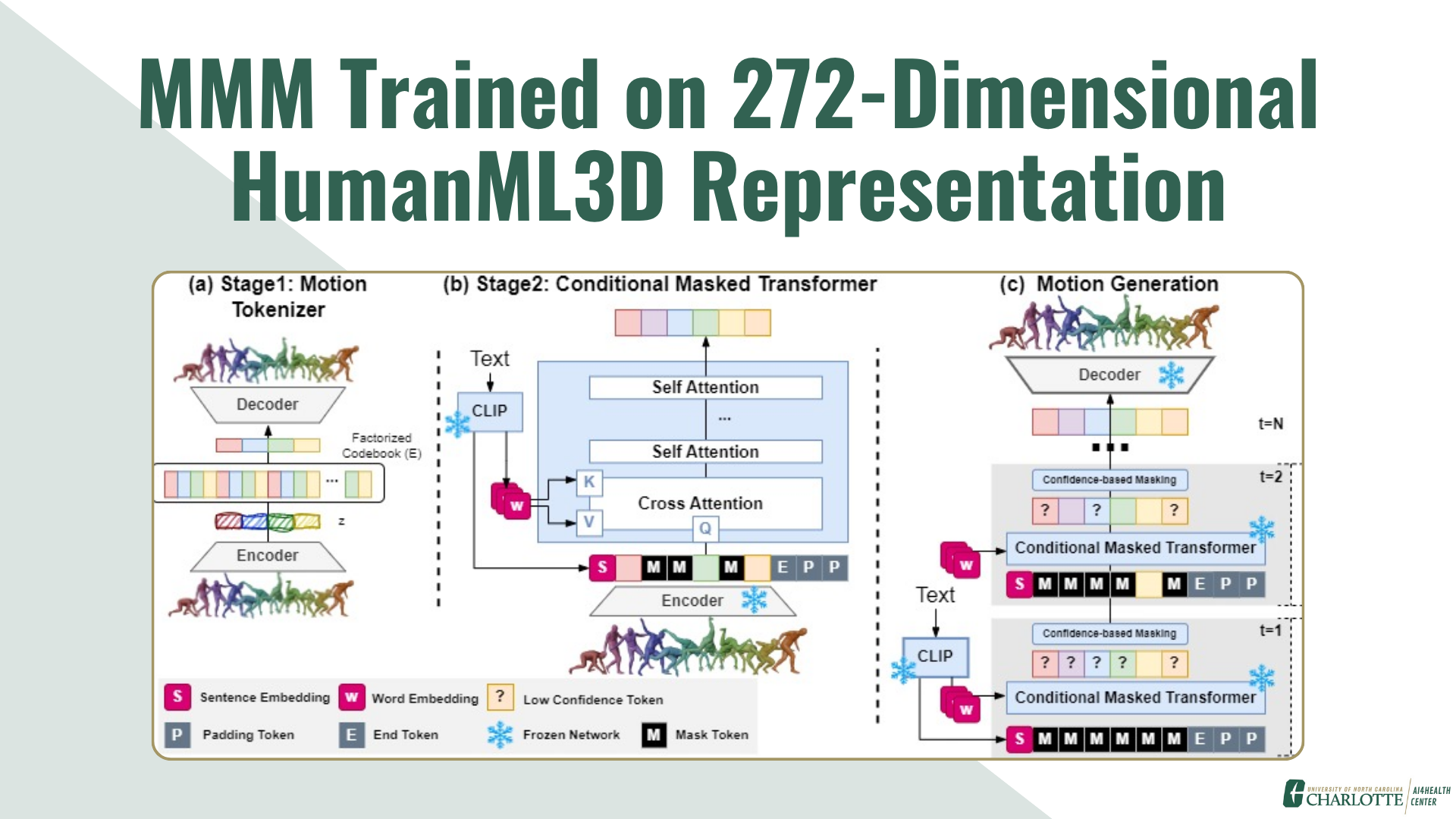
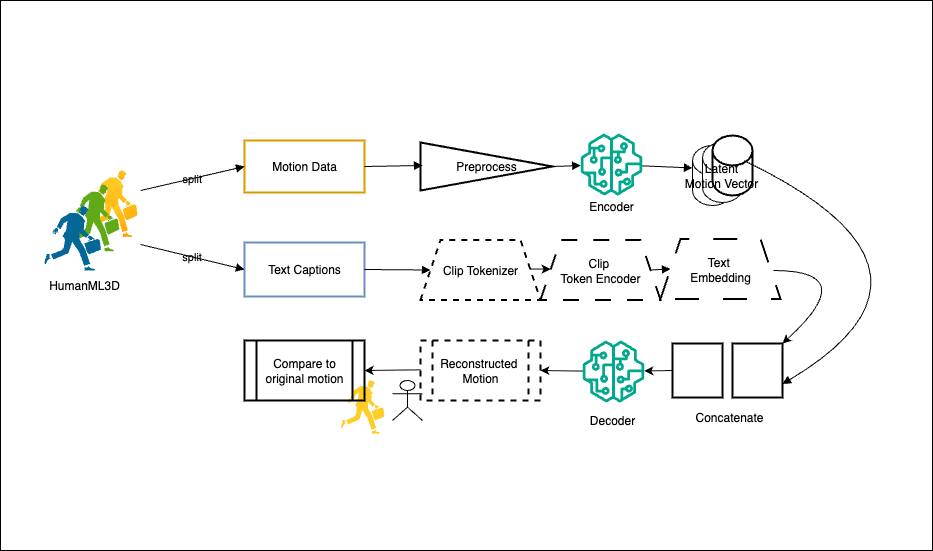
The MMM-272 project represents a significant advancement in text-to-motion generation technology. By upgrading from 263-dimensional to 272-dimensional motion representation, the model achieves superior motion quality and eliminates the need for Inverse Kinematics during BVH conversion. The system includes direct SMPL joint rotations in 6D format, preserving subtle motion details and producing animation-ready output for game engines and professional animation software.
The Challenge
Traditional text-to-motion models suffered from IK artifacts during BVH conversion and struggled to preserve fine-grained motion details like finger movements and joint twists. The existing 263-dimensional representation limited the model's ability to capture the full complexity of human motion, particularly for athletic and expressive movements.
The Approach & Solution
Implemented a comprehensive solution involving: (1) Upgraded VQVAE encoder/decoder architecture to handle 272-dimensional latent space with 512 codebook size and 2× temporal downsampling, (2) Trained a transformer with 9 layers, 1024 embedding dimensions, and 16 attention heads on 300K iterations, (3) Integrated direct SMPL rotation recovery in 6D format eliminating IK artifacts, (4) Developed a production-ready FastAPI server with pre-loaded models for real-time inference (~2-3 seconds), and (5) Built automatic BVH conversion pipeline for seamless integration with Unity, Unreal Engine, and Blender.
The Results
0.093
downState-of-the-art motion realism on HumanML3D dataset (lower is better)
60%
upReduction in BVH conversion errors vs position-based methods
2-3s
downReal-time generation with model pre-loading optimization
11.4%
upTop-3 text-motion matching accuracy



shoutout to Noah Hattout for designing the skills animation cube.